Handling Hotkeys in Timeline Storage at Twitter

As part of a larger migration of timeline storage a few years ago I worked on hotkey detection. It’s a, hopefully, interesting little feature. The simple overview of it was to detect hotkeys then signal them back to the user of the timeline storage cache.
A hotkey is data that is requested much more often then other pieces of data. This might be a timeline that is viewed because a user is popular, or maybe a bot went crazy. A hotkey is a problem because they can cause unexpected load on a single server. If we expect 1000 requests a second and suddenly a single key is being requested 1000 times on its own it can over load the server which will disrupt other requests and cause timeouts. These errors can cascade up the request path and turn into larger issues. This might be visible to the user.
The solution is to detect these hotkeys, then signal it back to the application requesting the data. Often after getting the signal, the application will store the data locally in a cache, so it will stop requesting the key from the storage. This prevents the storage server from getting overloaded by unexpected requests. This feature also has a secondary benefit of reducing request rates overall. On Twitter some users are just more popular than others. Timelines related to those popular users might be requested more often then other users. If we signal them as hot, timeline serving applications can cache those requests and avoid making those repeated requests to the back end storage system in the first place.
Background
The hot key detection I am going to describe is in place with a similar implementation in other services already. I am just talking about timeline storage though. I happened to work on the implementation, so I know it fairly well. The two systems involved are referred to as Haplo and Nighthawk. Engineers at Twitter have talked about both of these systems in detail in presentations and blog posts, but I’ll give a quick summary.
Haplo is the main timeline access system. It handles accessing timelines, reading and writing to timelines. It is a bit more complex in the features it provides and its place in the stack, but that is a real simple, tweet sized overview.
Nighthawk is the actual storage system that holds the data. It consists of an API layer that converts incoming Thrift requests into Redis commands and a cluster of Redis servers. The timeline itself is just a list in Redis. When a new tweet shows up, and you need to add it to a timeline, you might use LPUSH and add the tweet to the list. If you want to get a timeline, you use the users key and maybe use the LRANGE command to request it. Like Haplo, Nighthawk has a lot more going on, but more detail would be distracting.
Solution Overview
What we need to do is have requests to Nighthawk send back whether or not the request is hot. The first part is to have Redis detect the hotkey, then signal it back to the API layer of Nightawk. The next part is for the API to include the key status in its response to the application. In this case the requesting application is Haplo. An instance of a Haplo server then caches the hot request locally.
“The Algorithm”
No, Not that one
We already maintain a fork of Redis that is pretty heavily modified, so the decision to continue to change it was simple to make. The detection algorithm is relatively simple. We have a hotkey counter that consists of a queue of keys and a map that tracks how many times a key has been seen. When a key comes in we append it to the queue and increase the counter for that key by one. Then we pop off the oldest key from the queue and decrement it from the map by one. After, we calculate the percentage the incoming key makes up of the queue of seen keys. If the percentage calculated meets the configured percentage to be considered hot, we include in the response that is hot. Checking every key added noticeable latency to these requests, so we added an option to sample and only check every few keys. This was also configurable option.
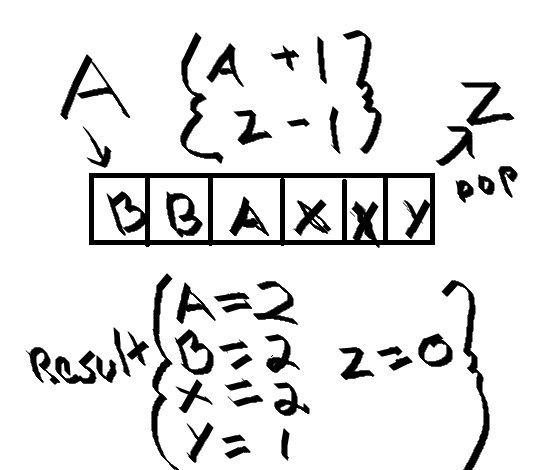
After having Key A come in, we check if its hot by doing 2/7 and get 28.6%. We probably wouldn't call this hot. Another "B" or "A" after might be though.To include this information in the Redis response we decided to add new commands, eg. LRANGE became LRANGE_HK. RESP is the protocol Redis uses for requests and responses, and it only has a few simple types to work with. The incoming request is only a list of commands as Strings. There was no way to encode that the request should include hotkey data and be sampled. The response to LRANGE is only a single array with the list contents. There was no way to include hotkey data in the response that would be backwards compatible with other clients or uses of list commands. These special hotkey commands would extract the key, sample it to see if it is hot, then continue on with the normal command and finally respond with the data and the hotkey status.
The response of these special commands was modified to use nested arrays as a structured response. The first index would be the key’s hot status. The second index would be the normal command response as if it was used normally.
Example if it was kind of like JSON
[
0: Status{Hot|Not Hot},
1: [ A, B, C, ... , ZZZ]
] Our API layer was now able to forward these list requests to Redis and handle the responses of the new commands. Modifying Thrift requests was a pretty typical thing to do so it wasn’t too exciting. In the API we also added the ability to cache the Redis responses. So if the API was seeing requests it was forwarding as hot we could cache them in Nighthawk and protect the backend Redis servers from becoming overwhelmed. It is easy to add more stateless apis than add more Redis servers. When Haplo received the response with a hotkey status it would also cache it.
Redis does have hot key detection, but it’s not in the server and requires connecting with the command line and running a tool last I saw. We wanted these systems to take care of themselves. We also have had this feature implemented in our fork of memcached for a while. Along with checking frequency, it can signal a key as hot when it uses to much bandwidth doing something similar. Could be cool to see this in the open source projects I think.
That is a little insight into how timeline storage hotkeys are detected and handled. I hope your takeaway was that it sounds cool, useful and ultimately not that complicated of a solution for a problem that is quite common.
Also, I am also open to hearing suggestions for topics to write about related to cache at Twitter if you have something you are curious about!
Wondering how data inconsistencies were handled, since you were caching data locally in the application. I believe there would be many instances of the application each can potentially have different version of same timeline. If user requests are distributed randomly among available set of application instances, it could be a problem right, I might see different data with each refresh?